듣게 된 배경
섹션 0. 강좌 소개
💡 계층 의존관계
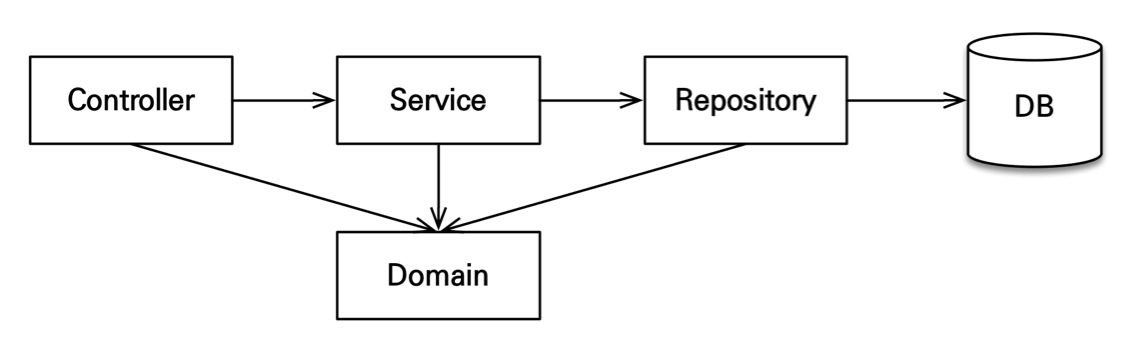
- controller : MVC의 컨트롤러가 모여 있는 곳.
컨트롤러는 서비스 계층을 호출하고, 결과를 뷰(JSP)에 전달함. - service : 서비스 계층에는 비즈니스 로직이 있고 트랜잭션을 시작함.
서비스 계층은 데이터 접근 계층인 리포지토리를 호출함. - repository : JPA를 직접 사용하는 계층.
여기서 엔티티 매니저를 사용해서 엔티티를 저장하고 조회함. - domain : 엔티티가 모여 있는 계층, 모든 계층에서 사용
💡 개발 순서
서비스 & 리포지토리 개발(비즈니스 로직 수행) → 테스트 케이스 작성(검증) → 컨트롤러 & 뷰
Ex)
- 회원 엔티티 코드 다시 보기
- 회원 리포지토리 개발
- 회원 서비스 개발
- 회원 기능 테스트
섹션 1. JPA 소개
0. JPA란?
- JPA(Java Persistence API)는 자바 진영의 ORM 기술 표준이다.
→ 그럼 ORM이란?
- ORM(Object-Relational Mapping)은 객체와 관계형 데이터베이스를 매핑한다는 뜻
- 객체와 테이블을 매핑 → 패러다임의 불일치 문제를 해결
Ex) 객체를 데이터베이스에 저장할 때, INSERT SQL을 직접 작성 X.
객체를 자바 컬렉션에 저장하듯이 ORM 프레임워크에 저장.
따라서 ORM이 적절한 INSERT SQL을 생성해, 데이터베이스에 객체를 저장해줌. - JPA를 사용해서 객체를 저장하는 코드
jpa.persist(member); // 저장- 조회할 때도 JPA를 통해 객체를 직접 조회하면 됨
Member member = jpa.find(memberId); // 조회
1. JPA를 왜 사용해야 하는가?
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 성능
- 데이터 접근 추상화와 벤더 독립성
- 표준
2. 생산성 - JPA와 CRUD
- 저장: jpa.persist(member)
- 조회: Member member = jpa.find(memberId)
- 수정: member.setName(“변경할 이름”)
- 삭제: jpa.remove(member)
3. JPA와 상속 - 예) 조회
- 개발자가 할일
Album album = jpa.find(Album.class, albumId); - 나머진 JPA가 처리
SELECT I.*, A.* FROM ITEM I JOIN ALBUM A ON I.ITEM_ID = A.ITEM_ID
(내 생각들)
- MyBatis를 사용했을 시 번거로움을 소개... 뼈맞음ㅠ
- 국비에서 MyBatis로 Mapper 이용해서 하는 걸로 배우고 플젝했는데, 슬프다 흑
- 이걸론 자체서비스 못 가겠구나... JPA 열심히 하자..!
- 구글링해보니 국비 과정이 다 비슷한데, 완전 SI 양성소다.
- 뭐 대기업 SI 가면 좋겠지만... 거기 갈 수 있는 사람들은 극소수.
대부분은 중소 SI 가서 인력파견 어쩌구 그런 거 하겠지..?ㅠ
섹션 2. JPA 시작하기
섹션 3. 영속성 관리
내부 동작 방식
- 영속 상태 : JPA가 관리하는 상태
0. JPA에서 가장 중요한 2가지
- 객체와 관계형 데이터베이스 매핑하기
(Object Relational Mapping) - 영속성 컨텍스트
1. 영속성 컨텍스트 이점
- 1차 캐시
- 동일성(identity) 보장
- 트랜잭션을 지원하는 쓰기 지연
(transactional write-behind) - 변경 감지(Dirty Checking)
- 지연 로딩(Lazy Loading)
2. 플러시
- 영속성 컨텍스트의 변경내용을데이터베이스에 반영
2 - 1. 플러시 발생
- 변경 감지
- 수정된 엔티티 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송
(등록, 수정, 삭제 쿼리)
2 - 2. 플러시는
- 영속성 컨텍스트를 비우지 않음
- 영속성 컨텍스트의 변경내용을 데이터베이스에 동기화
- 트랜잭션이라는 작업 단위가 중요 -> 커밋 직전에만 동기화하면 됨
3. 준영속 상태
- 영속 -> 준영속
- 영속 상태의 엔티티가 영속성 컨텍스트에서 분리(detached)
- 영속성 컨텍스트가 제공하는 기능을 사용 못함
⭐ 섹션 4. 영속성 관리 - 내가 보려고 정리
0. 엔티티 매니저(Entity Manager)
💡 매핑한 엔티티를 엔티티 매니저를 통해 어떻게 사용할까?
⭐ 엔티티 매니저는 엔티티를 저장, 수정, 삭제, 조회하는 등 엔티티와 관련된 모든 일을 처리함.
➡️ 이름 그대로 엔티티를 관리하는 관리자
private final EntityManager em;
public void save(Member member) {
em.persist(member);
}
public Member findOne(Long id) {
return em.find(Member.class, id);
}
💡 개발자 입장에서 엔티티 매니저란?
→ 엔티티를 저장하는 가상의 데이터베이스로 생각하면 됨
※ 참고
엔티티 매니저 팩토리 : 엔티티 매니저를 만드는 공장 (비용 ↑)
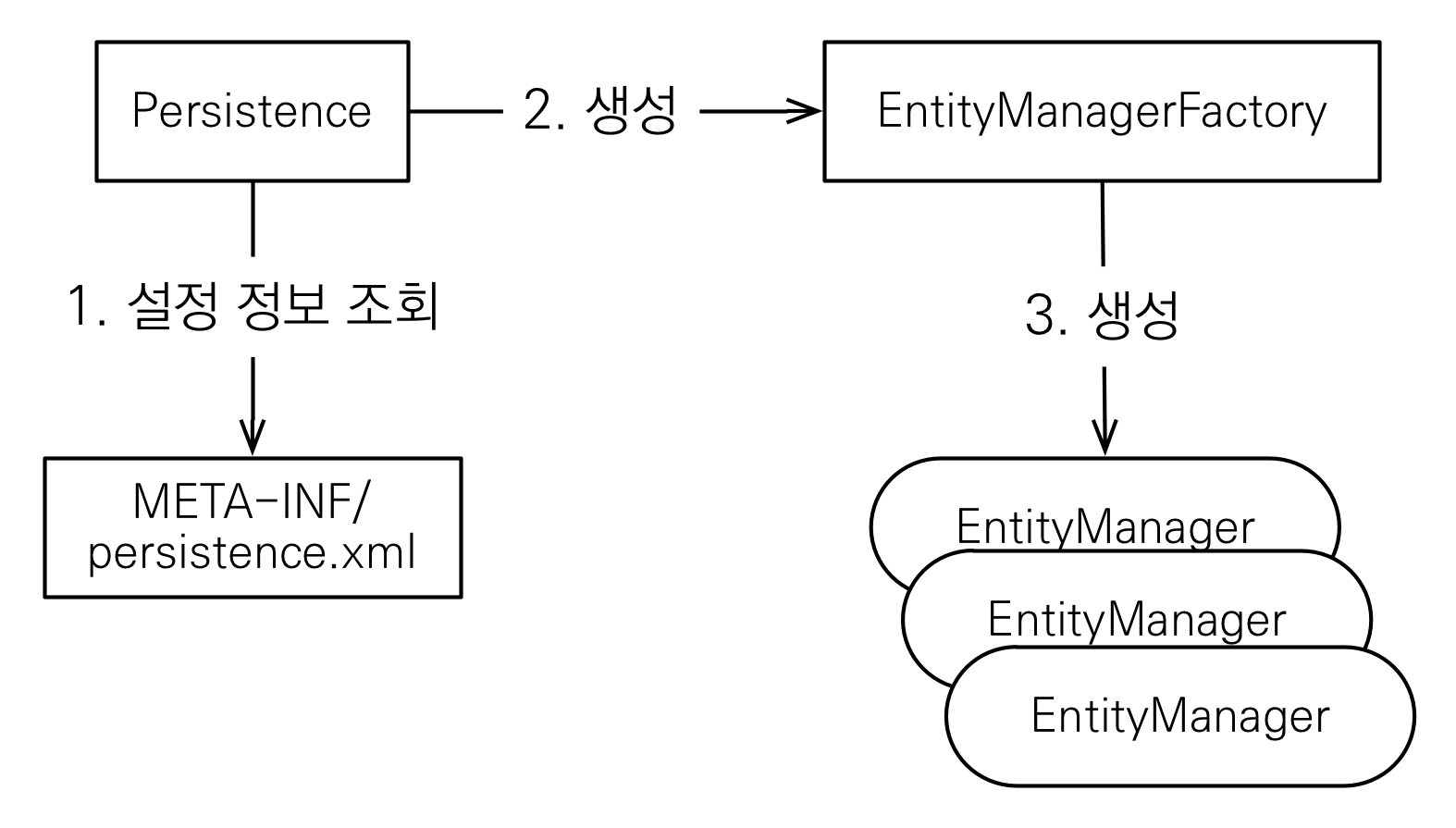
1. 영속성 컨텍스트란?
- 영속성 컨텍스트(persistence context) : 엔티티를 영구 저장하는 환경
→ 엔티티 매니저로 엔티티를 저장하거나 조회하면, 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리한다.
em.persist(member);
※ 참고
회원 엔티티를 저장한다는 것은,
persist() 메소드는 엔티티 매니저를 사용해서 회원 엔티티를 영속성 컨텍스트에 저장한다.
🚨 영속성 컨텍스트를 직접 본 적은 없을 것임.
∵ 논리적인 개념에 가깝고, 눈에 보이지도 않음.
영속성 컨텍스트는 엔티티 매니저를 생성할 때 하나 만들어진다.
또한 엔티티 매니저를 통해 영속성 컨텍스트에 접근할 수 있고, 영속성 컨텍스트를 관리할 수 있음.
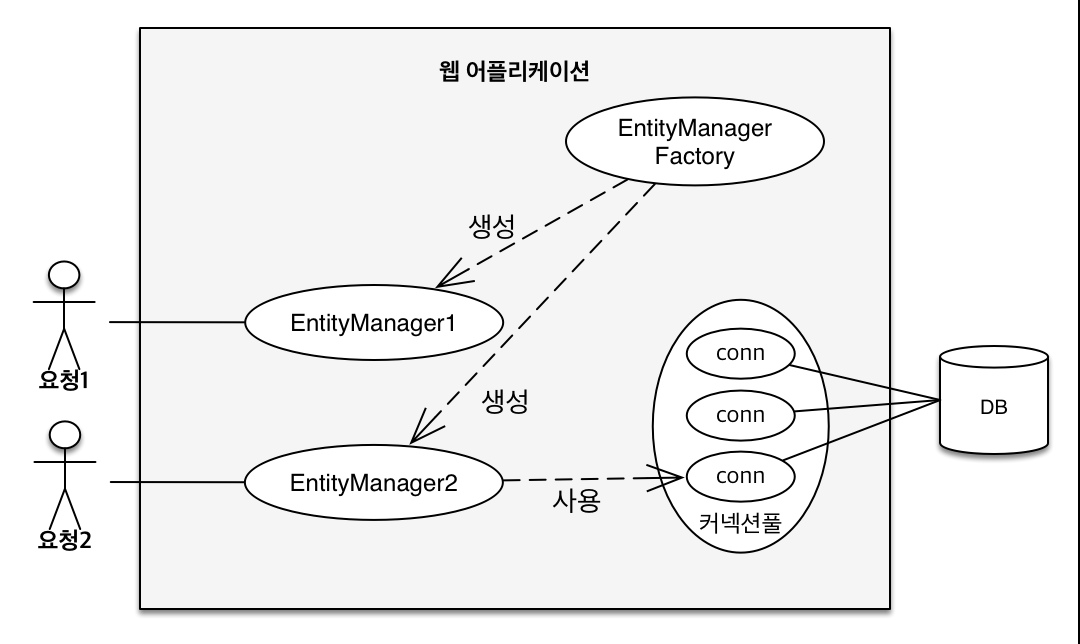
2. 엔티티의 생명주기
- 비영속(new/transient) : 영속성 컨텍스트와 전혀 관계가 없는 상태
- 영속(managed) : 영속성 컨텍스트에 저장된 상태
- 준영속(detached) : 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제(removed) : 삭제된 상태
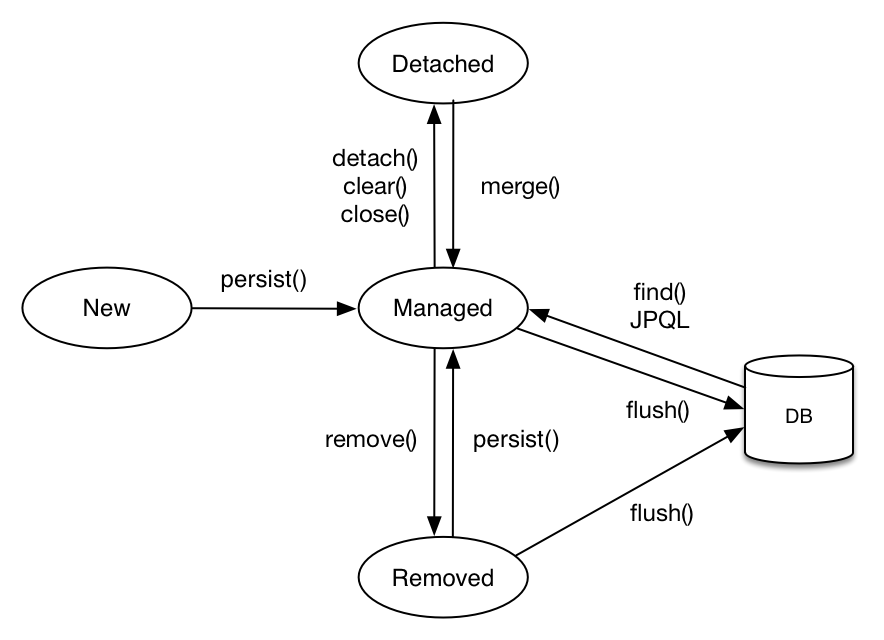
1. 비영속
- em.persist() 호출 전, 비영속 상태

- 엔티티 객체 생성
- 순수한 객체 상태 (저장X)
- 영속성 컨텍스트나 데이터베이스와는 전혀 관련 X
//객체를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
2. 영속
영속 상태 : 영속성 컨텍스트에 의해 관리된다.
- em.persist() 호출 후, 영속 상태

- 엔티티 매니저를 통해, 엔티티를 영속성 컨텍스트에 저장
- 영속성 컨텍스트가 관리하는 엔티티 : 영속 상태
※ em.find()나 JPQL을 사용해서 조회한 엔티티도 영속성 컨텍스트가 관리하는 영속 상태이다.
//객체를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername(“회원1”);
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
//객체를 저장한 상태(영속)
em.persist(member);
3. 준영속
- 영속성 컨텍스트가 관리하던 영속 상태의 엔티티를 영속성 컨텍스트가 관리하지 않는 상태
- 특정 엔티티를 준영영속 상태로 만들려면,호출
//회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태 em.detach(member);
또는
- em.close()를 호출해 영속성 컨텍스트를 닫음
- em.clear()를 호출해 영속성 컨텍스트를 초기화
4. 삭제
- 엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제
//객체를 삭제한 상태(삭제)
em.remove(member);
3. 영속성 컨텍스트의 특징
1. 영속성 컨텍스트와 데이터베이스 저장
💡 영속성 컨텍스트에 엔티티를 저장하면, 이 엔티티는 언제 데이터베이스에 저장될까?
→ JPA는 보통 트랜잭션을 커밋하는 순간 영속성 컨텍스트에 새로 저장된 엔티티를 데이터베이스에 반영한다.
→ 이것을 플러시(flush)라 한다.
2. 영속성 컨텍스트가 엔티티를 관리할 때의 장점
JPA는 왜 이렇게 영속성 컨텍스트를 사용하는 걸까?
→ 애플리케이션과 데이터베이스 사이에 영속성 컨텍스트라는 중간 계층을 만들었기 때문이다.
이렇게 중간 계층을 만들면 버퍼링, 캐싱 등을 할 수 있는 장점이 있다.
1. 1차 캐시

- 영속성 컨텍스트에는 1차 캐시가 존재하며, Map<KEY, VALUE>로 저장된다.
- entityManager.find() 메소드 호출 시 영속성 컨텍스트의 1차 캐시를 조회한다.
- 엔티티가 존재할 경우 해당 엔티티를 반환하고, 엔티티가 없으면 데이터베이스에서 조회 후 1차 캐시에 저장 및 반환한다.
2. 동일성(identity) 보장
- 하나의 트랜잭션에서 같은 키값으로 영속성 컨텍스트에 저장된 엔티티 조회 시, 같은 엔티티 조회를 보장한다.
- → 1차 캐시에 저장된 엔티티를 조회하기 때문.
3. 트랜잭션을 지원하는 쓰기 지연 (transactional write-behind)

- entityManager.persist()를 호출하면, 1차 캐시에 저장되는 것과 동시에 쓰기 지연 SQL 저장소에 SQL문이 저장된다.
- 이렇게 SQL을 쌓아두고 트랜잭션을 커밋하는 시점에, 저장된 SQL문들이 flush되면서 데이터베이스에 반영된다.
- 이렇게 모아둔 쿼리를 데이터베이스에 한 번에 보내기 때문에 성능을 최적화 할 수 있다.
4. 변경 감지 (Dirty Checking)
- JPA는 1차 캐시에 데이터베이스에 처음 불러온 엔티티의 스냅샷을 갖고 있다.
- 그리고 1차 캐시에 저장된 엔티티와 스냅샷을 비교 후 변경 내용이 있다면 UPDATE SQL문을 쓰기 지연 SQL 저장소에 담아둔다.
- 그리고 데이터베이스에 커밋 시점에 변경 내용을 자동으로 반영한다.
- 즉, 따로 update문을 호출할 필요가 없다.
5. 지연 로딩 (Lazy Loading)
4. 플러시 (flush)
- 영속성 컨텍스트이 변경 내용을 데이터베이스에 동기화하는 작업
- 이때 등록, 수정, 삭제한 엔티티를 데이터베이스에 반영함.
→ 쓰기 지연 SQL 저장소에 모인 쿼리를 데이터베이스에 보냄.
∴ 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화한 후,
실제 데이터베이스 트랜잭션을 커밋함.
💡 플러시를 실행하면?
- 변경 감지가 동작 → 영속성 컨텍스트에 있는 모든 엔티티를 스냅샷과 비교 → 수정된 엔티티 찾음
- 수정된 엔티티는 수정 쿼리를 만들어 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송함(등록, 수정, 삭제 쿼리)
☝️ 영속성 컨텍스트를 플러시 하는 방법 3가지
1. em.flush()를 직접 호출
영속성 컨텍스트를 강제로 플러시
2. 트랜잭션 커밋 시 플러시 자동 호출
데이터베이스에 변경 내용을 SQL로 전달하지 않고,
트랜잭션만 커밋하면 어떤 데이터도 DB에 반영 X.
∴트랜잭션을 커밋하기 전,
꼭 플러시를 호출해 영속성 컨텍스트의 변경 내용을 DB에 반영해야 함.
→ JPA는 이런 문제를 예방하기 위해 트랜잭션을 커밋할 때 플러시를 자동 호출함.
3. JPQL 쿼리 실행 시 플러시 자동 호출
JPQL이나 Criteria 같은 객체지향 쿼리를 호출할 때도 플러시가 실행됨.
※ 식별자 기준으로 조회하는 find()는 메소드를 호출할 때는 플러시 실행 X
'Spring > JPA' 카테고리의 다른 글
| JPA 강의 6 - 프록시와 연관관계 관리, 값 타입 (0) | 2022.12.19 |
|---|---|
| JPA 강의 5 - 고급 매핑 (0) | 2022.12.19 |
| JPA 강의 4 - 다양한 연관관계 매핑 (0) | 2022.12.19 |
| JPA 강의 3 - 연관관계 매핑 기초 (0) | 2022.12.19 |
| JPA 강의 2 - 엔티티 매핑 (0) | 2022.12.19 |