출처 : 자바 ORM 표준 JPA 프로그래밍 - 기본편
섹션 11. 객체지향 쿼리 언어2 - 중급 문법
1. JPQL - 경로 표현식
1 - 1. JPQL - 경로 표현식
- .(점)을 찍어 객체 그래프를 탐색하는 것

1 - 2. 경로 표현식 용어 정리
- 상태 필드(state field): 단순히 값을 저장하기 위한 필드
(ex: m.username) - 연관 필드(association field): 연관관계를 위한 필드
• 단일 값 연관 필드:
@ManyToOne, @OneToOne, 대상이 엔티티(ex: m.team)
• 컬렉션 값 연관 필드:
@OneToMany, @ManyToMany, 대상이 컬렉션(ex: m.orders)
1 - 3. 경로 표현식 특징
- 상태 필드(state field): 경로 탐색의 끝, 탐색X
- 단일 값 연관 경로: 묵시적 내부 조인(inner join) 발생, 탐색O 🚨
- 컬렉션 값 연관 경로: 묵시적 내부 조인 발생, 탐색X
• FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능
1 - 4. 실무 조언 ✔️
💡 가급적 묵시적 조인 대신에 명시적 조인 사용
💡 가급적 JPQL이랑 SQL이랑 맞춰서 해라
- 명시적 조인: join 키워드 직접 사용
• select m from Member m join m.team t - 묵시적 조인: 경로 표현식에 의해 묵시적으로 SQL 조인 발생
(내부 조인만 가능)
• select m.team from Member m
2. JPQL - 페치 조인(fetch join) ⭐
⭐⭐⭐ 실무에서 정말정말 중요함 ⭐⭐⭐
2 - 0. 페치 조인(fetch join)
- SQL 조인 종류X
- JPQL에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
- join fetch 명령어 사용
- 나랑 연관된 애를 다 끌고 온다는 뜻 ✔️
2 - 1. 엔티티 페치 조인
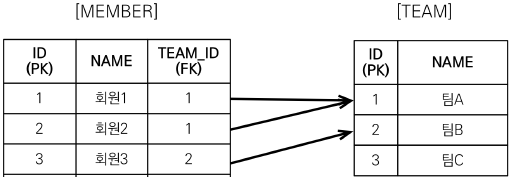
- 회원을 조회하면서 연관된 팀도 함께 조회(SQL 한 번에)
- SQL을 보면 회원 뿐만 아니라 팀(T.*)도 함께 SELECT
- [JPQL]
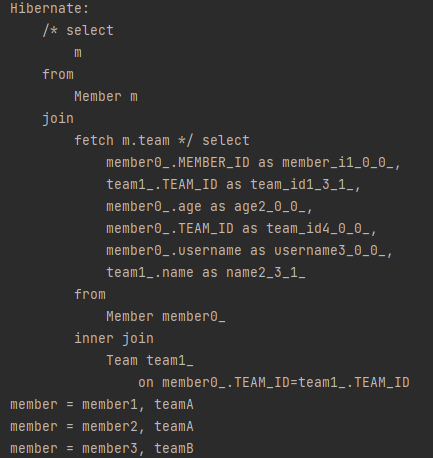
select m from Member m join fetch m.team - [SQL]
SELECT M., *T.*** FROM MEMBER M - INNER JOIN TEAM T* ON M.TEAM_ID=T.ID
→ 즉시로딩해서 가져올 때랑 똑같다.
ex) ⭐
-> 이 경우 예제...
Team teamA = new Team();
teamA.setName("teamA");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("teamB");
em.persist(teamB);
Member member1 = new Member();
member1.setUsername("member1");
member1.setTeam(teamA);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("member2");
member2.setTeam(teamA);
em.persist(member2);
Member member3 = new Member();
member3.setUsername("member3");
member3.setTeam(teamB);
em.persist(member3);
em.flush();
em.clear();
String query = "select m from Member m";
List<Member> members = em.createQuery(query, Member.class)
.getResultList();
for (Member member : members) {
System.out.println("member = " + member.getUsername() + ", " + member.getTeam().getName());
// member1, teamA : SQL 날림
// member2, teamA : 1차 캐시 (SQL 날린 거 저장된 거에서 가져옴)
// member3, teamB : SQL 날림
// 회원 100명 -> N + 1
// 회원 조회를 위한 쿼리를 '한번' 날리면, 100번(N번) 돈다.
// 즉시로딩이든 지연로딩이든 다 발생함
// 따라서 fetch join으로 해결해야 함
// (select m from Member m join fetch m.team)
}
tx.commit();- fetch join을 하지 않은 경우 : select m from Member m
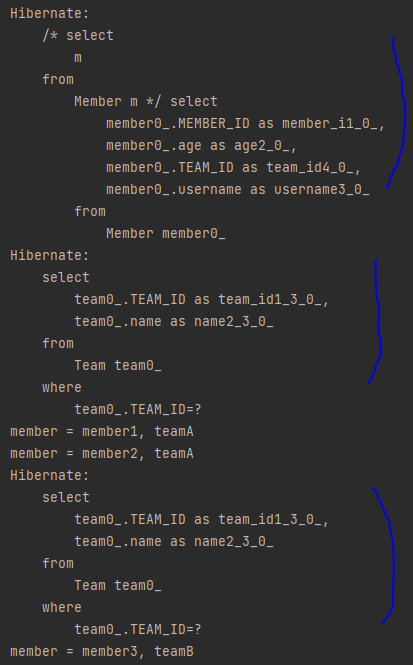
→ 쿼리 3번 나감 (memberA와 memberB의 팀이 같기 때문)
→ 만약 각 member들이 팀이 다 다르다면? 엄청난 쿼리 날림
- fetch join을 한 경우 : select m from Member m join fetch m.team
2 - 2. 컬렉션 페치 조인
- 일대다 관계, 컬렉션 페치 조인
- [JPQL]
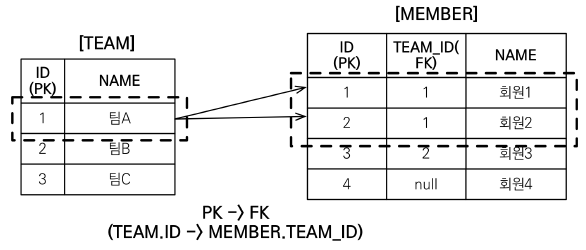
select t
from Team t join fetch t.members
where t.name = ‘팀A' - [SQL]
SELECT T., *M.***
FROM TEAM T
INNER JOIN MEMBER M ON T.ID=M.TEAM_ID
WHERE T.NAME = '팀A'
ex) ⭐
-> 이 경우 예제...
Team teamA = new Team();
teamA.setName("teamA");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("teamB");
em.persist(teamB);
Member member1 = new Member();
member1.setUsername("member1");
member1.setTeam(teamA);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("member2");
member2.setTeam(teamA);
em.persist(member2);
Member member3 = new Member();
member3.setUsername("member3");
member3.setTeam(teamB);
em.persist(member3);
em.flush();
em.clear();
String query = "select t from Team t join fetch t.members";
List<Team> teams = em.createQuery(query, Team.class)
.getResultList();
for (Team team : teams) {
System.out.println("team = " + team.getName() + " | members = " + team.getMembers().size());
}
tx.commit();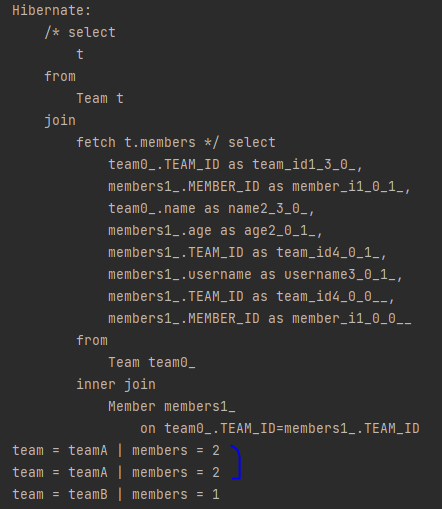
-> 데이터 뻥튀기 : teamA 입장에서는 한 개인데, 멤버가 2명이라 2 row가 됨
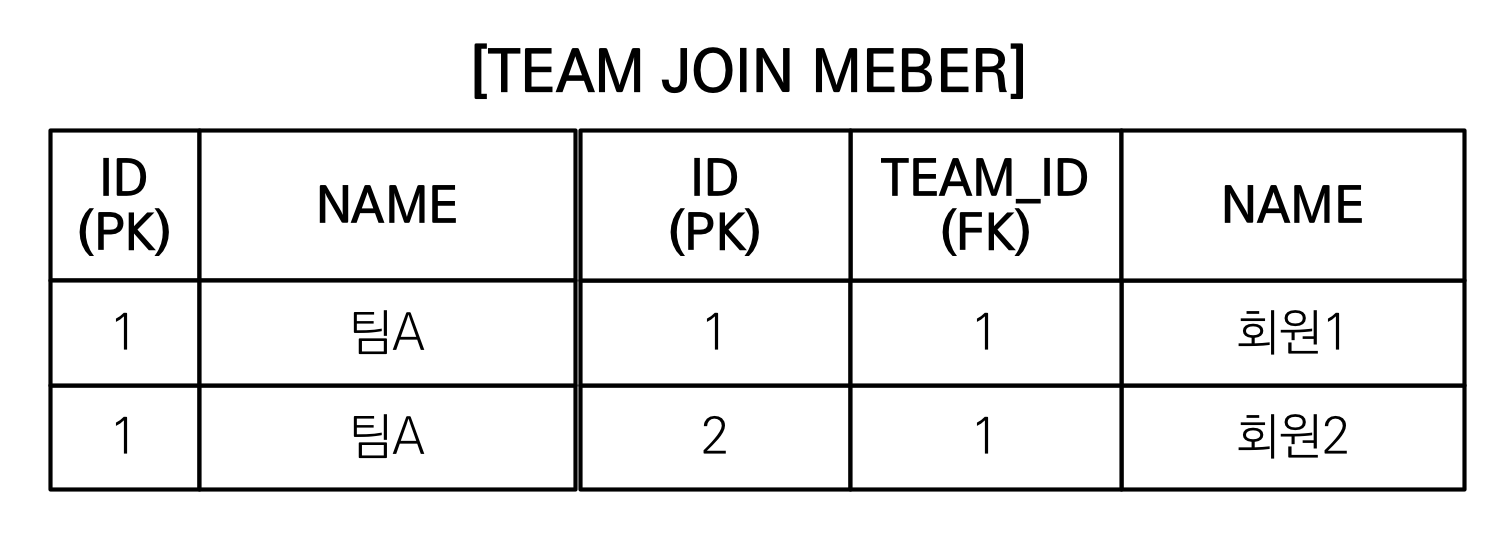
2 - 3. 페치 조인과 DISTINCT
- SQL의 DISTINCT는 중복된 결과를 제거하는 명령
- JPQL의 DISTINCT 2가지 기능 제공
- SQL에 DISTINCT를 추가
- 애플리케이션에서 엔티티 중복 제거
- SQL에 DISTINCT를 추가하지만 데이터가 다르므로 SQL 결과에서 중복제거 실패
(완전히 같아야만 distinct가 됨)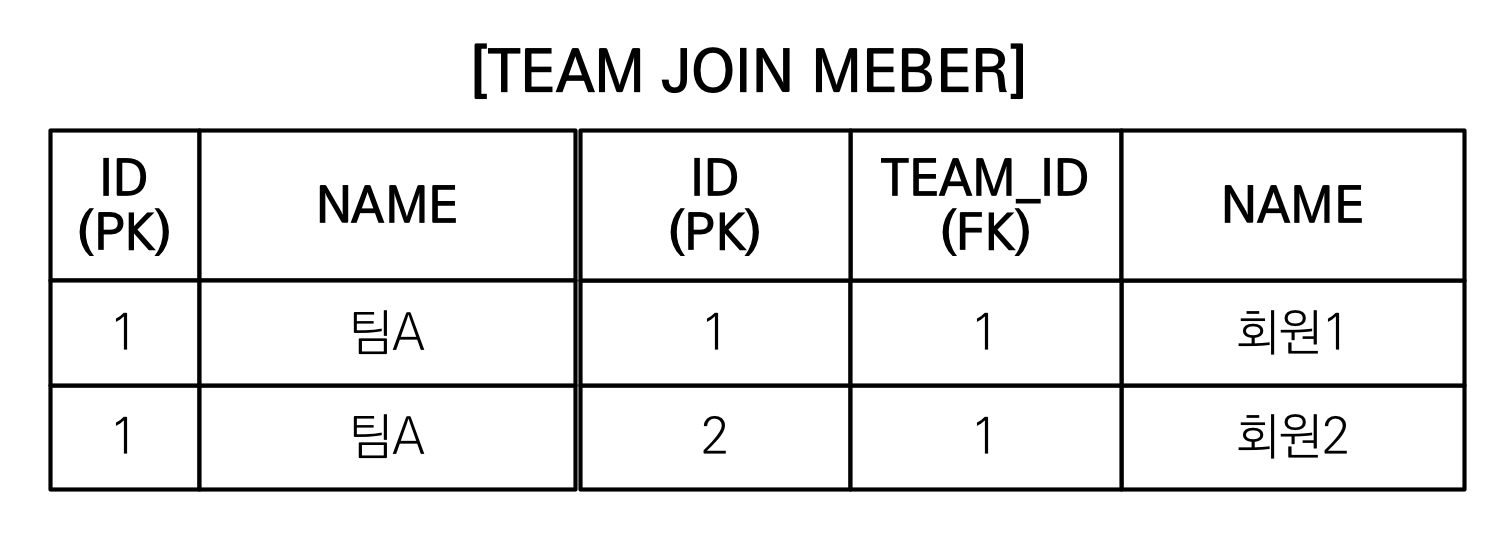
- DISTINCT가 추가로 애플리케이션에서 중복 제거시도
- 같은 식별자를 가진 Team 엔티티 제거
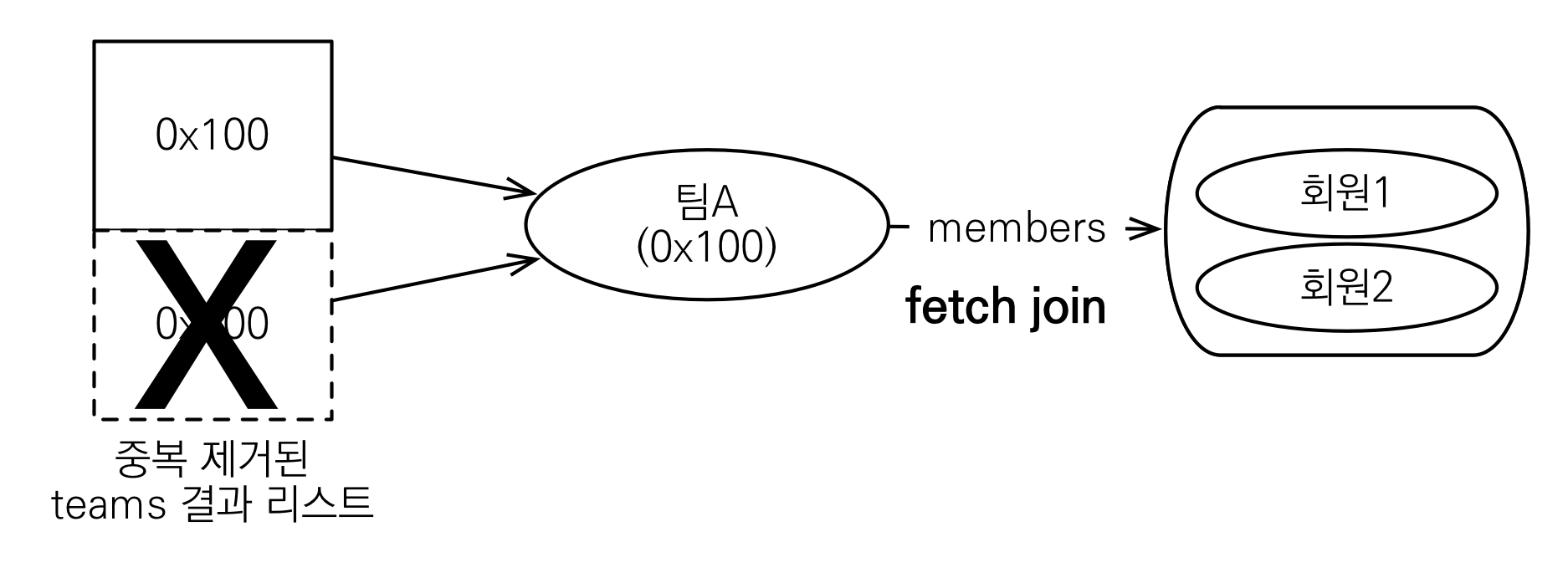
2 - 4. 페치 조인과 일반 조인의 차이
- 일반 조인 실행시 연관된 엔티티를 함께 조회하지 않음
- JPQL은 결과를 반환할 때 연관관계 고려X
- 단지 SELECT 절에 지정한 엔티티만 조회할 뿐
- 여기서는 팀 엔티티만 조회하고, 회원 엔티티는 조회X
(select t from Team t join t.members t)
- 페치 조인을 사용할 때만 연관된 엔티티도 함께 조회(즉시 로딩)
(select t from Team t join fetch t.members)
(페치 조인을 사용한다는 건, 사실상 즉시 로딩이 일어난다고 보면 됨) - 페치 조인은 객체 그래프를 SQL 한번에 조회하는 개념
- 대부분의 N + 1 문제를 이걸로 해결 함
2 - 5. 페치 조인의 특징과 한계
- 페치 조인 대상에는 별칭을 줄 수 없음
(ex. select t from Team t join fetch t.members as m)
• 하이버네이트는 가능, 가급적 사용X - 둘 이상의 컬렉션은 페치 조인 할 수 없음
- 컬렉션을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.
• 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
• 하이버네이트는 경고 로그를 남기고 메모리에서 페이징(매우 위험) - 연관된 엔티티들을 SQL 한 번으로 조회 - 성능 최적화
- 최적화가 필요한 곳은 페치 조인 적용
- (JPA에서 성능 문제의 7-80%는 거의 N + 1인데, 거의 페치 조인으로 다 잡힘)*
'Spring > JPA' 카테고리의 다른 글
| 스프링 데이터 JPA - (1) (0) | 2022.12.19 |
|---|---|
| JPA 활용 2 - API 개발과 성능 최적화 (0) | 2022.12.19 |
| JPA 강의 7 - 객체지향 쿼리 언어 1 (기본 문법) (0) | 2022.12.19 |
| JPA 강의 6 - 프록시와 연관관계 관리, 값 타입 (0) | 2022.12.19 |
| JPA 강의 5 - 고급 매핑 (0) | 2022.12.19 |