출처 : 실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화
섹션 1. API 개발 기본
1 - 1. 회원 등록 API
- @Controller + @ResponseBody == @ RestController (스프링 MVC 강의에 나옴)
- @RequestBody : JSON으로 온 Body를 Member에 그대로 매핑해서 쫙 넣어준다.
즉, JSON data를 Member로 쫙 바로 바꿔준다. (MVC에 관련된 내용)
🚨 API를 만들 때는 엔티티를 파라미터로 받지 말아라 & 엔티티를 외부에 노출해서도 안 됨.
즉, API는 항상 요청이 들어오거나 나가는 건 전부 다 엔티티를 사용하지 않고,
DTO(객체)를 사용해서 등록이랑 응답을 받는 걸 권장함.
// 예시 코드 : Member 엔티티 대신 별도의 DTO(CreateMemberRequest)를 받음 (API의 정석)
@PostMapping("/api/v2/members")
public CreateMemberResponse saveMemberV2(@RequestBody @Valid CreateMemberRequest request) {
Member member = new Member();
member.setName(request.getName());
Long id = memberService.join(member);
return new CreateMemberResponse(id);
}
@Data
static class CreateMemberRequest {
private String name;
}
- Postman으로 보내기
POST : http://localhost:8080/api/v2/members{ "name": "hello" }
1 - 2. 회원 수정 API
- 등록이랑 수정은 API가 다르다.
- 별도의 Reponse를 가져간다.
- DTO는 그냥 대충 데이터만 왔다갔다하는 것이기 때문에, 크게 로직이 있는 게 아니다.
- 변경감지 써라
@PutMapping("/api/v2/members/{id}")
public UpdateMemberResponses updateMemberV2(@PathVariable("id") Long id, @RequestBody @Valid UpdateMemberRequest request) {
memberService.update(id,request.getName());
Member findMember = memberService.findOne(id);
return new UpdateMemberResponses(findMember.getId(), findMember.getName());
}
@Data
static class UpdateMemberRequest {
private String name;
}
@Data
@AllArgsConstructor
static class UpdateMemberResponses {
private Long id;
private String name;
}
- Postman으로 보내기
PUT : http://localhost:8080/api/v2/members/1{ "name": "new-hello" }
1 - 3. 회원 조회 API
- ddl-auto: none
@GetMapping("/api/v2/members")
public Result memberV2() {
List<Member> findMembers = memberService.findMembers();
List<MemberDto> collect = findMembers.stream()
.map(m -> new MemberDto(m.getName()))
.collect(Collectors.toList());
return new Result(collect);
}
@Data
@AllArgsConstructor
static class Result<T> {
private T data;
}
@Data
@AllArgsConstructor
static class MemberDto {
private String name;
}
- Postman으로 보내기
GET : http://localhost:8080/api/v2/members
- 결과
{ "data": [ { "name": "member1" }, { "name": "member2" } ] }
1 - 4. 결론
⭐ API를 만들 땐,
엔티티를 외부에 직접 반환하지 말고,
중간에 API 스펙에 맞는 DTO를 만들고 활용해라!
섹션 2. API 개발 고급 - 준비
주제 : 조회에 대한 API를 어떻게 성능 최적화를 할까?
Ex) N + 1 문제 같은...
- ddl-auto: create
⭐섹션 3. API 개발 고급-지연 로딩과 조회 성능 최적화⭐
주문 + 배송정보 + 회원을 조회하는 API를 만들자.
지연 로딩 때문에 발생하는 성능 문제를 단계적으로 해결해보자.
3 - 1. 간단한 주문 조회 V1: 엔티티를 직접 노출
엔티티 그대로 반환하지 말아라 (외부 노출 X)
- 지연로딩 : DB에서 안 끌고 옴
- 프록시 기술 : JPA 기본편에 자세히 설명되어 있음
🚨 주의
엔티티를 직접 노출할 때는 양방향 연관관계가 걸린 곳은
꼭! 한곳을 @JsonIgnore 처리 해야 한다.
안그러면 양쪽을 서로 호출하면서 무한 루프가 걸린다.
※ 참고
앞에서 계속 강조했듯이
정말 간단한 애플리케이션이 아니면 엔티티를 API 응답으로 외부로 노출하는 것은 좋지 않다.
따라서 Hibernate5Module를 사용하기 보다는
DTO로 변환해서 반환하는 것이 더 좋은 방법이다.
🚨 주의
지연 로딩(LAZY)을 피하기 위해 즉시 로딩(EARGR)으로 설정하면 안된다!
즉시 로딩 때문에 연관관계가 필요 없는 경우에도
데이터를 항상 조회해서 성능 문제가 발생할 수 있다.
즉시 로딩으로 설정하면 성능 튜닝이 매우 어려워 진다.
항상 지연 로딩을 기본으로 하고,
성능 최적화가 필요한 경우에는 페치 조인(fetch join)을 사용해라! (V3에서 설명)
3 - 2. 간단한 주문 조회 V2: 엔티티를 DTO로 변환
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAll(new OrderSearch());
// ORDER(N) 2개라면, 2번 루프가 돈다.
// N + 1 -> 1(첫 번째 쿼리 : ORDERS 가져옴) + 회원 N + 배송 N
// 이 예제의 경우라면, 1 + 2 + 2 == 5, 총 5개의 쿼리가 실행됨.
List<SimpleOrderDto> result = orders.stream()
.map(o -> new SimpleOrderDto(o))
.collect(Collectors.toList());
return result;
}
@Data
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName(); // LAZY 초기화
orderDate = order.getOrderDate(); // 주문시간
orderStatus = order.getStatus();
address = order.getDelivery().getAddress(); // LAZY 초기화
}
}→ 🚨 Lazy 로딩으로 인한 데이터베이스 쿼리가 너무 많이 호출됨!
- ORDER -> SQL 1번 -> 결과 주문수 2개
- ORDER가 2번이니, 총 5개의 쿼리가 호출됨.
- ORDER
- MEMBER
- DELIVERY
- MEMBER
- DELIVERY
● 엔티티를 DTO로 변환하는 일반적인 방법이다.
● 쿼리가 총 1 + N + N번 실행된다. (v1과 쿼리수 결과는 같다.)
● order 조회 1번(order 조회 결과 수가 N이 된다.)
● order -> member 지연 로딩 조회 N 번
● order -> delivery 지연 로딩 조회 N 번
● 예) order의 결과가 4개면 최악의 경우 1 + 4 + 4번 실행된다.(최악의 경우)
● 지연로딩은 영속성 컨텍스트에서 조회하므로, 이미 조회된 경우 쿼리를 생략한다.
3 - 3. 간단한 주문 조회 V3: 엔티티를 DTO로 변환 - 페치 조인 최적화
// OrderSimpleController.java
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
List<SimpleOrderDto> result = orders.stream()
.map(o -> new SimpleOrderDto(o))
.collect(Collectors.toList());
return result;
}
// OrderRepository.java
public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class
).getResultList();
}
select
order0_.order_id as order_id1_6_0_,
member1_.member_id as member_i1_4_1_,
delivery2_.delivery_id as delivery1_2_2_,
order0_.delivery_id as delivery4_6_0_,
order0_.member_id as member_i5_6_0_,
order0_.order_date as order_da2_6_0_,
order0_.status as status3_6_0_,
member1_.city as city2_4_1_,
member1_.street as street3_4_1_,
member1_.zipcode as zipcode4_4_1_,
member1_.name as name5_4_1_,
delivery2_.city as city2_2_2_,
delivery2_.street as street3_2_2_,
delivery2_.zipcode as zipcode4_2_2_,
delivery2_.status as status5_2_2_
from
orders order0_
inner join
member member1_
on order0_.member_id=member1_.member_id
inner join
delivery delivery2_
on order0_.delivery_id=delivery2_.delivery_id→ 엔티티를 페치 조인(fetch join)을 사용해서 쿼리 1번에 조회
→ 페치 조인으로 order -> member , order -> delivery 는
이미 조회 된 상태 이므로 지연로딩 X
→ 연관된 걸 다 끌고오기 때문에 다시 한 번 더 최적화 해야함
3 - 4. 간단한 주문 조회 V4: JPA에서 DTO로 바로 조회
※ 3 - 3번까지는 엔티티를 조회한 다음에 DTO로 중간에 변환
select
order0_.order_id as col_0_0_,
member1_.name as col_1_0_,
order0_.order_date as col_2_0_,
order0_.status as col_3_0_,
delivery2_.city as col_4_0_,
delivery2_.street as col_4_1_,
delivery2_.zipcode as col_4_2_
from
orders order0_
inner join
member member1_
on order0_.member_id=member1_.member_id
inner join
delivery delivery2_
on order0_.delivery_id=delivery2_.delivery_id→ 내가 원하는 것만 select 해줌
→ V3보다는 성능 최적화에서 좀 더 낫다. (하지만 성능 차이가 많이 나진 않음)
- 일반적인 SQL을 사용할 때 처럼 원하는 값을 선택해서 조회
- new 명령어를 사용해서 JPQL의 결과를 DTO로 즉시 변환
- SELECT 절에서 원하는 데이터를 직접 선택하므로 DB -> 애플리케이션 네트웍 용량 최적화 (생각보다 미비)
- 리포지토리 재사용성 떨어짐, API 스펙에 맞춘 코드가 리포지토리에 들어가는 단점
3 - 5. 정리
엔티티를 DTO로 변환하거나, DTO로 바로 조회하는 두가지 방법은 각각 장단점이 있다.
둘중 상황에 따라서 더 나은 방법을 선택하면 된다.
엔티티로 조회하면 리포지토리 재사용성도 좋고, 개발도 단순해진다.
따라서 권장하는 방법은 다음과 같다.
쿼리 방식 선택 권장 순서
- 우선 엔티티를 DTO로 변환하는 방법을 선택한다.
- 필요하면 페치 조인으로 성능을 최적화 한다. -> 대부분의 성능 이슈가 해결된다.
- 그래도 안되면 DTO로 직접 조회하는 방법을 사용한다.
- 최후의 방법은 JPA가 제공하는 네이티브 SQL이나 스프링 JDBC Template을 사용해서 SQL을 직접 사용한다.
섹션 4. API 개발 고급 - 컬렉션 조회 최적화
● 주문내역에서 추가로 주문한 상품 정보를 추가로 조회하자.
Order 기준으로 컬렉션인 OrderItem 와 Item 이 필요하다.
● 앞의 예제에서는 toOne(OneToOne, ManyToOne) 관계만 있었다.
이번에는 컬렉션인 일대다 관계(OneToMany)를 조회하고, 최적화하는 방법을 알아보자.
4 - 1. 주문 조회 V1: 엔티티 직접 노출
엔티티를 직접 노출하므로 좋은 방법은 아니다.
4 - 2. 주문 조회 V2: 엔티티를 DTO로 변환
- OrderItem 조차도 DTO로 변환해서 해야 함.
껍데기만 DTO로 하라는 게 아님.
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(toList());@Data
static class OrderItemDto {
private String itemName;//상품 명
private int orderPrice; //주문 가격
private int count; //주문 수량
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
- 지연 로딩으로 너무 많은 SQL 실행
- SQL 실행 수
- order 1번
- member , address N번(order 조회 수 만큼)
- orderItem N번(order 조회 수 만큼)
- item N번(orderItem 조회 수 만큼)
4 - 3. 주문 조회 V3: 엔티티를 DTO로 변환 - 페치 조인 최적화
- 페치 조인으로 SQL이 1번만 실행됨
- distinct 를 사용한 이유는 1대다 조인이 있으므로 데이터베이스 row가 증가한다.
그 결과 같은 order엔티티의 조회 수도 증가하게 된다.
JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면,
애플리케이션에서 중복을 걸러준다.
이 예에서 order가 컬렉션 페치 조인 때문에 중복 조회 되는 것을 막아준다. - 단점
- 페이징 불가능
🚨 메모리에서 페이징 처리는 매우 위험
🚨 컬렉션 둘 이상에 페치 조인을 사용하면 안된다.
4 - 4. 주문 조회 V3.1: 엔티티를 DTO로 변환 - 페이징과 한계 돌파
페이징과 한계 돌파
- 컬렉션을 페치 조인하면 페이징이 불가능하다.
- 이 경우 하이버네이트는 경고 로그를 남기고 모든 DB 데이터를 읽어서 메모리에서 페이징을 시도한다.
최악의 경우 장애로 이어질 수 있다.
한계 돌파
💡 그러면 페이징 + 컬렉션 엔티티를 함께 조회하려면 어떻게 해야할까?
- 먼저 ToOne(OneToOne, ManyToOne) 관계를 모두 페치조인 한다.
ToOne 관계는 row수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다. - 컬렉션은 지연 로딩으로 조회한다.
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size , @BatchSize 를 적용한다.
- hibernate.default_batch_fetch_size: 글로벌 설정
- @BatchSize: 개별 최적화
- 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
⭐ 섹션 5. API 개발 고급 - 실무 필수 최적화
⭐ 잘 알고 넘어가야 함!
OSIV와 성능 최적화
- Open Session In View: 하이버네이트
- Open EntityManager In View: JPA
(관례상 모두 OSIV라 한다.)
OSVI는 영속성 컨텍스트를 뷰까지 열어둔다는 뜻이다.
영속성 컨텍스트가 살아있으면 엔티티는 영속 상태로 유지된다.
따라서 뷰에서도 지연로딩을 사용할 수 있다.
OSIV ON
OSIV의 핵심 : 뷰에서도 지연 로딩이 가능하도록 하는 것
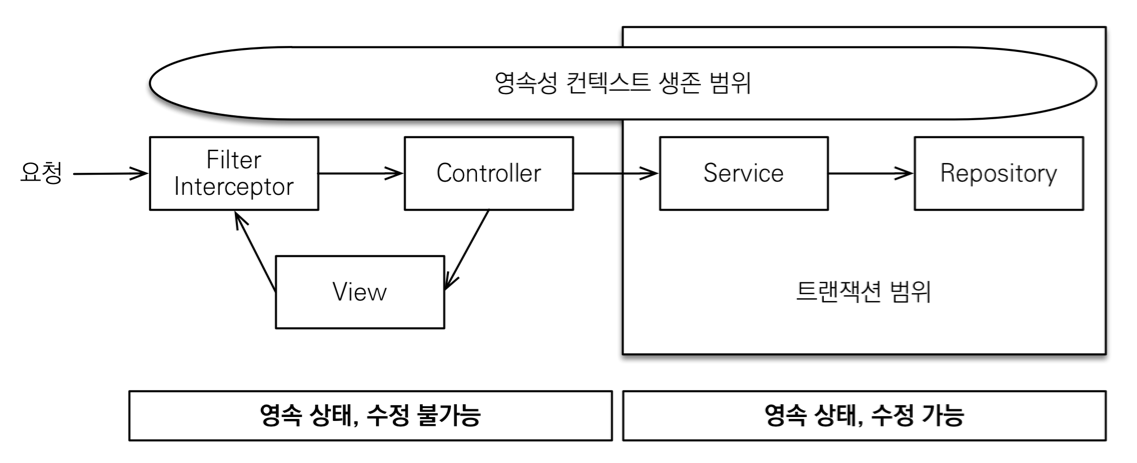
- spring.jpa.open-in-view : true 기본값
WARN 4496 --- [ restartedMain] JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
영속성 컨텍스트랑 데이터베이스 커넥션은 굉장히 밀접하게 매칭이 되어있다.
- 그럼 언제 JPA가 데이터베이스 커넥션을 획득하는가?
→ 기본적으론, 데이터베이스 트랜잭션을 시작할 때 JPA 영속성 컨텍스트가 데이터베이스 커넥션을 가져온다.
→ Service 계층에서 트랜잭션(@Transactional)을 시작하는 시점에 DB를 가져온다.
- 그럼 언제 DB에 돌려줘야할까?
→ OSIV가 켜져있으면(ON), @Transactional 끝나도, 커넥션을 반환하지 않는다.
- OSIV는 트랜잭션이 끝나도 영속성 컨텍스트를 끝까지 살려둠
→ API 경우, API가 유저에 반환이 될 때까지
→ 화면인 경우엔, View 템플릿이 렌더링 등을 할때까지
- 즉, 요청이 들어와서 응답이 나갈 때까지 끝까지 살아있음.
→ 그래서 지금까지 View Template이나 API 컨트롤러에서 지연 로딩이 가능했던 것
🚨 장점
- 엔티티를 적극 활용해서 LAZY 로딩 같은 기술을 컨트롤러와 뷰에서 적응 활용할 수 있음
→ 중복도 줄이고, 투명하게 레이지 로딩을 끝까지 해나갈 수 있다.
→ 코드의 유지보수성을 높일 수 있음.
🚨 단점
- 실시간 트래픽이 중요한 애플리케이션에서는 커넥션이 모자랄 수 있음
→ 너무 오랜시간동안 데이터베이스 커넥션 리소스를 사용하기 때문
→ 결국 장애로 이어진다.
일반적인 애플리케이션에서는 데이터베이스 트랜잭션이 끝나면,
커넥션 반환해버리면 됨.
근데 이것은 데이터베이스 커넥션을 끝까지 물고있다가
고객에서 response 주는 타이밍에서 커넥션을 반환함.
OSIV OFF
장점 : 데이터베이스의 커넥션을 굉장이 짧게 유지함
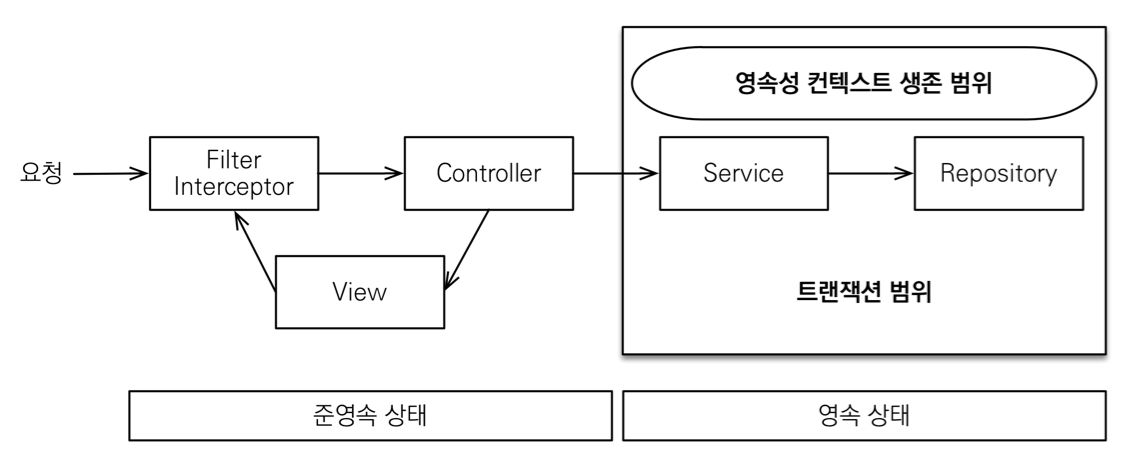
- spring.jpa.open-in-view: false OSIV 종료
→ OSIV를 끄면 트랜잭션을 종료할 때 영속성 컨텍스트를 닫고, 데이터베이스 커넥션도 반환함
→ 따라서 커넥션 리소스를 낭비하지 않음 - OSIV를 끄면 모든 지연로딩을 트랜잭션 안에서 처리해야 한다.
→ 따라서 지금까지 작성한 많은 지연 로딩 코드를 트랜잭션 안으로 넣어야 하는 단점
→ 그리고 view template에서 지연로딩이 동작하지 않음
→ 결론적으로 트랜잭션이 끝나기 전에 지연 로딩을 강제로 호출해 두어야 한다.
💡 이런 문제를 해결하려면?
→ 프리젠테이션 계층에서 엔티티를 수정하지 못하게 막으면 됨!
- 엔티티를 읽기 전용 인터페이스로 제공
→ 엔티티를 직접 노출하는 대신에,
읽기 전용 메소드만 제공하는 인터페이스를 프리젠테이션 계층에 제공함. - 엔티티 레핑
- DTO만 반환
커멘드와 쿼리 분리
실무에서 OSIV를 끈 상태로 복잡성을 관리하는 좋은 방법이 있다.
→ 바로 Command와 Query를 분리하는 것이다.
예시
- OrderService
- OrderService: 핵심 비즈니스 로직
- OrderQueryService: 화면이나 API에 맞춘 서비스 (주로 읽기 전용 트랜잭션 사용)
→ 보통 서비스 계층에서 트랜잭션을 유지한다.
두 서비스 모두 트랜잭션을 유지하면서 지연 로딩을 사용할 수 있다.
'Spring > JPA' 카테고리의 다른 글
| 스프링 데이터 JPA - (2) (0) | 2022.12.20 |
|---|---|
| 스프링 데이터 JPA - (1) (0) | 2022.12.19 |
| JPA 강의 8 - 객체지향 쿼리 언어 2, JPA N + 1 문제 (중급 문법) (0) | 2022.12.19 |
| JPA 강의 7 - 객체지향 쿼리 언어 1 (기본 문법) (0) | 2022.12.19 |
| JPA 강의 6 - 프록시와 연관관계 관리, 값 타입 (0) | 2022.12.19 |